
全部課程


發(fā)布時(shí)間: 2023-04-06 17:48:36
Hadoop是為處理大型文件所設(shè)計(jì)的,在小文件的處理上效率較低,然而在實(shí)際生產(chǎn)環(huán)境中,需要Hadoop處理的數(shù)據(jù)往往存放在海量小文件中。因此,高效處理小文件對于提高Hadoop的性能至關(guān)重要。這里的小文件是指小于 HDFS中一個(gè)塊(Block)大小的文件。
Hadoop處理小文件有兩種方法:壓縮小文件和創(chuàng)建序列化文件。
Hadoop在存儲海量小文件時(shí),需要頻繁訪問各節(jié)點(diǎn),非常耗費(fèi)資源。如果某個(gè)節(jié)點(diǎn)上存放1000萬個(gè)600Byte大小的文件,那么該節(jié)點(diǎn)上至少需要提供4 GB的內(nèi)存。為了節(jié)省資源,海量小文件在存儲到HDFS之前,需要進(jìn)行壓縮。
1.Hadoop壓縮格式
Hadoop進(jìn)行文件壓縮的作用:減少存儲空間占用,降低網(wǎng)絡(luò)負(fù)載。這兩點(diǎn)對于Hadoop存儲和傳輸海量數(shù)據(jù)非常重要。Hadoop常用的壓縮格式,如表所示。
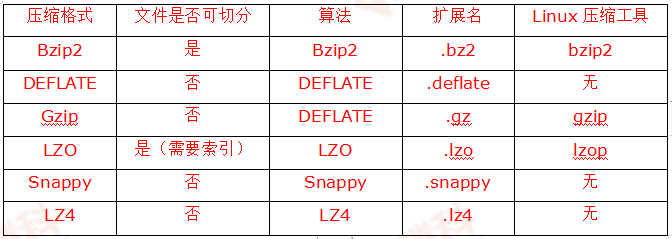
2.編解碼器
編解碼器(Codec)是指用于壓縮和解壓縮的設(shè)備或計(jì)算機(jī)程序。Hadoop中的編壓縮解碼器主要是通過Hadoop的一些類來實(shí)現(xiàn)的, 如表所示。

對于LZO壓縮格式,Hadoop實(shí)現(xiàn)壓縮編解碼器的類不在org.apache.hadoop.io.compress包中,可前往GitHub官方網(wǎng)站下載。
3.壓縮格式的效率
對上述6種壓縮格式的壓縮效率、解壓效率、壓縮占比進(jìn)行測試,測試結(jié)果如下。
壓縮效率 (由高到低): Snappy > LZ4 > LZO > Gzip > DEELATE > Bzip2
解壓效率 (由高到低): Snappy > LZ4 > LZO > Gzip > DEELATE > Bzip2
壓縮占比 (由小到大): Bzip2 < DEELATE < Gzip < LZ4 < LZO < Snappy
在實(shí)際生產(chǎn)環(huán)境中,可以參考以上的測試結(jié)果,根據(jù)業(yè)務(wù)需要做出恰當(dāng)?shù)倪x擇。
創(chuàng)建序列文件主要是指創(chuàng)建SequenceFile(順序文件)和MapFile(映射文件)。
1.SequenceFile
(1)SequenceFile簡介。
SequenceFile是存儲二進(jìn)制鍵值(Key-Value)對的持久數(shù)據(jù)結(jié)構(gòu)。通過SequenceFile可以將若干小文件合并成一個(gè)大的文件進(jìn)行序列化操作,實(shí)現(xiàn)文件的高效存儲和處理。
(2)SequenceFile的內(nèi)部結(jié)構(gòu)
SequenceFile由一個(gè)文件頭(Header)和隨后的一條或多條記錄(Record)組成(如圖所示)。Header的前三個(gè)字節(jié)SEQ(順序文件代碼),隨后的一個(gè)字節(jié)是SequenceFile的版本號。Header還包括Key類的名稱、Value類的名稱、壓縮細(xì)節(jié)、Metadata(元數(shù)據(jù))、Sync Marker(同步標(biāo)識)等。Sync Marker的作用在于可以讀取SequenceFile任意位置的數(shù)據(jù)。
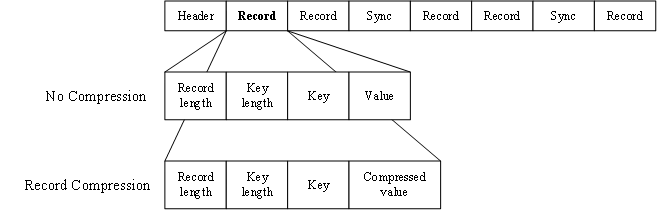
記錄有無壓縮、記錄壓縮、塊壓縮三種壓縮形式,默認(rèn)為無壓縮。
① 當(dāng)采用無壓縮(No Compress)時(shí),每條記錄由記錄長度、鍵長度、鍵、值組成,將鍵與值序列化寫入SequenceFile。
② 當(dāng)采用記錄壓縮(Record Compress)時(shí),只壓縮值,不壓縮鍵,其他方面與無壓縮類似。
③ 塊壓縮(Block Compress)利用記錄間的相似性進(jìn)行壓縮,一次性壓縮多條記錄,比單條記錄的壓縮方法壓縮效率更高。
當(dāng)采用塊壓縮時(shí),多條記錄被壓縮成默認(rèn)1MB的數(shù)據(jù)塊,每個(gè)數(shù)據(jù)塊之前插入同步標(biāo)識。數(shù)據(jù)塊由表示數(shù)據(jù)塊字節(jié)數(shù)的字段和壓縮字段組成,其中,壓縮字段包括鍵長度、鍵、值長度、值。

微信

公眾號









