
全部課程


發(fā)布時(shí)間: 2021-08-02 10:10:18
HPC( High Performance Computing,高性能計(jì)算)領(lǐng)域主要是解決計(jì)算密集型、海量數(shù)據(jù)處理等業(yè)務(wù)的計(jì)算需求,如科學(xué)研究、氣象預(yù)報(bào)、計(jì)算模擬等。如何提高計(jì)算能力、極致化應(yīng)用性能成為當(dāng)前 HPC 領(lǐng)域各大平臺(tái)最關(guān)鍵的課題之一,編譯器在其中發(fā)揮著至關(guān)重要的作用。
畢昇編譯器作為一款基于鯤鵬平臺(tái)的高性能編譯器,在編譯算法、加速指令集、 Autotuner 等方面對(duì)應(yīng)用場(chǎng)景進(jìn)行了深度的優(yōu)化,為開發(fā)者提供高效的性能加持。本期由畢昇編譯器工程師為你介紹鯤鵬的性能優(yōu)化利器——畢昇編譯器如何釋放鯤鵬的強(qiáng)勁算力。
了解畢昇編譯器
畢昇編譯器是基于 LLVM,針對(duì)鯤鵬平臺(tái)進(jìn)行了深度優(yōu)化的高性能編譯器。除支持 LLVM 通用功能之外,對(duì)以下三個(gè)方面進(jìn)行了增強(qiáng),使得鯤鵬平臺(tái)的強(qiáng)勁算力能夠較大限度地得到釋放。
高性能編譯算法:編譯深度優(yōu)化,內(nèi)存優(yōu)化增強(qiáng),自動(dòng)矢量化等,大幅提升指令和數(shù)據(jù)呑吐量。
加速指令集:結(jié)合 NEON/SVE 等內(nèi)嵌指令技術(shù),深度優(yōu)化指令編譯和運(yùn)行時(shí)庫(kù),發(fā)揮鯤鵬架構(gòu)極致算力。
AI 迭代調(diào)優(yōu):內(nèi)置 AI 自學(xué)習(xí)模型,自動(dòng)優(yōu)化編譯配置,迭代提升程序性能,完成最優(yōu)編譯。

畢昇編譯器特性架構(gòu)圖
當(dāng)前畢昇編譯器已廣泛應(yīng)用于多種 HPC 典型場(chǎng)景,如氣象、安防、流體力學(xué)等,性能優(yōu)勢(shì)已初步體現(xiàn)。其中,SPEC CPU 2017 benchmark 跑分平均優(yōu)于 GCC 20%以上,HPC 典型氣象應(yīng)用 WRF 優(yōu)于 GCC 10%。
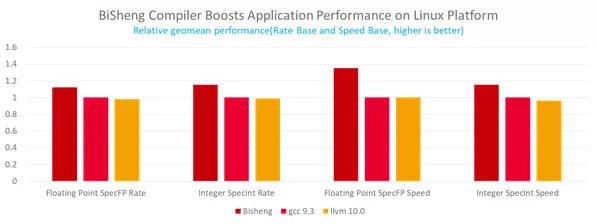
畢昇編譯器與開源編譯器SPEC CPU 2017 跑分對(duì)比
畢昇編譯器典型優(yōu)化場(chǎng)景及其優(yōu)化原理
結(jié)構(gòu)體內(nèi)存布局優(yōu)化—大幅提升緩存命中率,突破訪存瓶頸
SPEC CPU 2017 benchmark 中的 mcf 子項(xiàng)是對(duì)內(nèi)存要求較高的應(yīng)用,它是一款叫做MCF的大規(guī)模交通規(guī)劃軟件的核心代碼。其瓶頸代碼如下圖左邊所示。
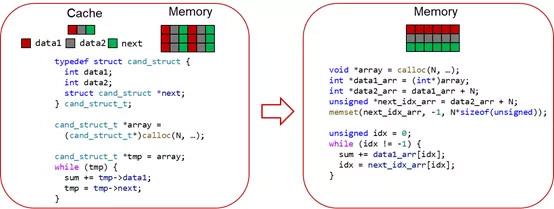
結(jié)構(gòu)體優(yōu)化原理示意圖
可見在 struct 中,data1 的使用率較高,而 data2 是不使用的。然而由于源代碼中,數(shù)據(jù)的排布是以結(jié)構(gòu)體數(shù)組的形式排布。按照一般編譯器的編譯方式,拿數(shù)據(jù)時(shí)每次都會(huì)將整個(gè)結(jié)構(gòu)體放到 cache 里面,導(dǎo)致大量不參與計(jì)算的 data2 也被加載到了 cache 中,造成高速內(nèi)存空間的浪費(fèi)和性能的損耗。
畢昇編譯器會(huì)通過(guò)用戶標(biāo)記的結(jié)構(gòu)體聲明,或者通過(guò)自動(dòng)檢查循環(huán)中適合優(yōu)化的內(nèi)存場(chǎng)景,確認(rèn)優(yōu)化點(diǎn)。然后通過(guò)將結(jié)構(gòu)體數(shù)組變?yōu)閿?shù)組結(jié)構(gòu)體的方式(如上圖右),將有效數(shù)據(jù)緊湊排布,從而提高 cache 命中率和應(yīng)用性能。經(jīng)測(cè)試,此優(yōu)化可以對(duì) mcf 子項(xiàng)帶來(lái)50%的性能提升。
自動(dòng)矢量化—計(jì)算效率提升的秘訣
鯤鵬平臺(tái)支持 Armv8 NEON 矢量化指令集。當(dāng)前支持32個(gè)128位的矢量寄存器,指令可以同時(shí)操作4*32或2*64的數(shù)據(jù)。畢昇編譯器依托這種硬件優(yōu)勢(shì)做了大量?jī)?yōu)化,包括 SLP(superword-level parallelism) 矢量化和循環(huán)自動(dòng)矢量化。例如在 SPEC CPU 2017 benchmark 中處理視頻流格式轉(zhuǎn)換的x264子項(xiàng)中,畢昇編譯器會(huì)自動(dòng)識(shí)別并使用 uabd 和 udot 這類高效向量指令完成計(jì)算來(lái)替換標(biāo)量指令,增大單時(shí)鐘周期的數(shù)據(jù)處理量, 從而大幅提升計(jì)算效率。對(duì)于 x264 子項(xiàng),這項(xiàng)優(yōu)化可有效提升其30%的計(jì)算效率。
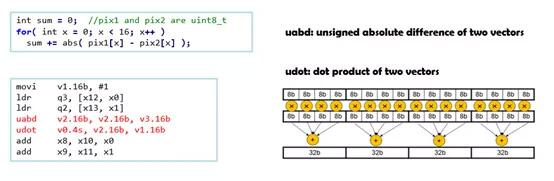
矢量化優(yōu)化示例
Autotuner—基于機(jī)器學(xué)習(xí)快速獲取最優(yōu)編譯配置
如何獲取性能最優(yōu)編譯選項(xiàng)是編譯器使用中常見的問(wèn)題,往往需要長(zhǎng)時(shí)間的手動(dòng)選項(xiàng)調(diào)優(yōu)。為了減少這其中的工作量,使得用戶能快速找到最優(yōu)的優(yōu)化選項(xiàng),畢昇編譯器自研了基于 ML 的自動(dòng)搜索技術(shù)(ML-based Search) 的 Autotuner 工具。
Autotuner 的調(diào)優(yōu)流程由兩個(gè)階段組成:初始編譯階段(initial compilation)和調(diào)優(yōu)階段(tuning process),如下圖所示:
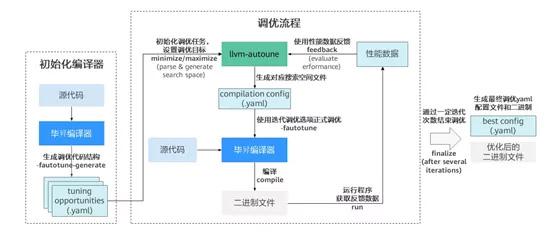
Autotuner 使用流程?
簡(jiǎn)單來(lái)說(shuō),在初始編譯階段,編譯器會(huì)通過(guò)用戶指定的調(diào)優(yōu)方向,對(duì)可調(diào)優(yōu)的代碼區(qū)間進(jìn)行標(biāo)記。在隨后的調(diào)優(yōu)階段,Autotuner 會(huì)根據(jù)搜索算法對(duì)不同的優(yōu)化區(qū)間生成不同的編譯配置。然后使用此配置編譯運(yùn)行,并根據(jù)運(yùn)行性能的反饋來(lái)迭代優(yōu)化配置參數(shù)。最后經(jīng)過(guò)給定迭代次數(shù)后找出最優(yōu)配置供用戶使用。在實(shí)踐過(guò)程中,通過(guò) Autotuner 對(duì) Coremark Benchmark 進(jìn)行調(diào)優(yōu)可以獲取5%以上的收益。
以上介紹的三個(gè)優(yōu)化特性分別是畢昇編譯器在中前端算法優(yōu)化、后端指令優(yōu)化、迭代調(diào)優(yōu)中較具代表性、在各自領(lǐng)域?qū)π阅芴嵘憩F(xiàn)最佳的三個(gè)特性。除以上介紹的三個(gè)優(yōu)化特性之外,畢昇編譯器在軟件預(yù)取、循環(huán)優(yōu)化、分支預(yù)測(cè)、指針壓縮等編譯優(yōu)化技術(shù)均有探索且取得了顯著的收益
上一篇: oracle考試流程
下一篇: 使用 Spring Boot、Oracle 自治數(shù)據(jù)庫(kù)和OCI Vault構(gòu)建安全的云原生應(yīng)用

微信

公眾號(hào)









